머신러닝의 기초와 용어
K-Nearest Neighbors
1. K는 임의의 숫자를 의미(Hyperparameter)
2. 두 관측치의 거리가 가까우면 Y도 비슷함
3. K 개의 주변 관측치의 Class에 대한 majority voting(다수결)
4. Distance-based model, instance-based learning

1) 거리가 가장 가까운 관측치 3개를 골라 봤더니 그림처럼 발생
2) 두 관측치 사이의 거리를 측정할 수 있는 방법

5. K의 영향
- K는 KNN에서 Hyperparameter를 의미
- K가 클수록 Underfitting, 작을수록 Overfitting (K가 적을 때는 설정값이 적기 때문에 자세하게 분해해서 학습을 하는 것이면, K가 크다면 설정값이 많아서 설정한대로만 움직이기 때문에 단순하게 학습이 될 것이다.)
6. 최적의 Validation K 값을 찾는게 목표
Logistic Regression
1. Logistic Regression의 배경
- 선형 회귀 분석의 클래식한 버전이라고 볼 수 있음 = 다중 선형 회귀분석(y는 연속형)
- 목적 : 수치형 설명변수 X와 종속변수 Y간의 관계를 선형으로 가정하고 이를 가장 잘 표현할 수 있는 회귀 계수를 추정
- Loss란 오차(MSE와 같은 예시), Minimize loss란 오차를 최소화 하자란 의미
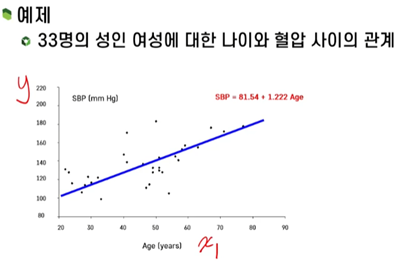
- Logistic function을 사용해서 이와 같이 이름이 지어짐
2. Logistic Regression의 필요성
- 종속 변수의 속성이 이진 변수인 경우(0 or 1)
* 그렇다면 확률값을 선형 회귀분석으로 사용하는 것이 타당한가?

* 예측값이 (0 or 1)로 이루어져 있다면 x(독립변수)가 많아질수록 y가 무한대로 커질 수 있기에 범위에 대한 문제가 생길 수 있음
* 이러한 이진형 형태의 분류문제 때문에 Logistic regression을 사용해서 문제점을 개선하고자 함

- 위와 같이 의미없는 그래프가 발생함 => Logistic regression이 필요함
3. Logistic regression

- 분류형 데이터에서 값들의 범위를 지정한 후에 함수를 적용함

- Cross-entropy Loss : 각 관측치와 해당 클래스의 확률 값을 곱해서 모두 더해서 (-, 마이너스, 원래 Loss 값이 음수이므로)를 취해주면 구할 수 있음
! 최종적으로 Linear Regression은 선형 회귀(예측값들의 값을 선으로 만든 것)
! Logistic regression은 범주형태로 만들어서 확률값을 만들고 계산
최적화와 모형 학습
1. Machine Learning and Optimization

- Loss를 최적화 시켜야 좋은 머신러닝이 될 수 있음
2. Linear Regression


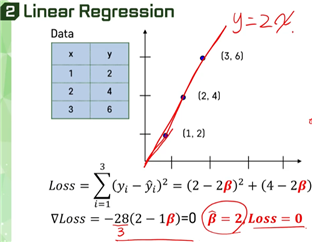
- Optimization(최적화)란 Loss 값이 제일 작을 때를 의미
3. Loss Function of Neural networks
- 신경망처럼 굉장히 복잡한 모양의 모델도 많음
경사하강법 개요
1. Iterative Algorithm-based Optimization
- 가파르게 함수를 줄일 수 있는 함수를 찾고 적용하고 다시 찾고 하는 최적화
2. Gradient Descect


- tc는 step 사이즈이다. (Hyperparameter 중 하나)
- 경사도를 이용하여 Loss를 최적화 하는 방법
- 결과적으로 함수에 대한 미분을 하면 구할 수 있음
출처 : http://www.kmooc.kr/courses/course-v1:SSUk+SSMOOC20K+2022_T1/about / 수업 내용을 듣고 정리함
'개발 > (3) 머신러닝(ML), 딥러닝(DL)' 카테고리의 다른 글
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 2 (0) | 2023.03.27 |
|---|---|
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 1 (0) | 2023.03.27 |
| 추천시스템 분석 입문하기 (T아카데미) 정리 (0) | 2023.02.15 |
| YOLO 공식문서 번역 및 학습 (0) | 2022.12.25 |
| K-MOOC 파이썬 머신러닝 공부 1일차 (0) | 2022.11.21 |