728x90
반응형
추천시스템 분석 입문하기 (T아카데미) 정리
추천시스템의 이해
- 강의 목차

- 추천시스템이란?
- 사용자에게 상품을 제안하는 소프트웨어 도구이자 기술
- 어떤 사용자에게 어떤 상품을 어떻게 추천할지?
- 기업에서의 추천시스템
- 당근마켓 = 다른 사람들이 같이 본 상품을 추천
- 카카오 = 해당 글과 유사한 글들을 추천
- 추천시스템의 역사 (역사 순서에 따라 설명 진행)
- 연관분석
- 연관분석이란
- 룰기반의 모델, 상품과 상품 사이에 어떠한 연관이 있는지 찾아내는 알고리즘
- 얼마나(frequent) 같이 구매됐는가?
- A 라는 아이템을 구매한 사용자는 B 라는 아이템도 구매를 하는가?
- 연관분석의 규칙 평가 지표
- support (지지도)
- 조건절 A에서 얼마나 구매할지의 확률 (단순히 선택된 것이라고 생각하자.)
- confidence (신뢰도)
- A 아이템을 구매 후에 B 아이템을 구매할 확률
- lift (향상도)
- A 아이템 구매와 B 아이템 구매가 동시에 얼마나 발생하는지의 확률
- support (지지도)
- 연관분석의 규칙 생성 (아이템 구매의 모든 경우의 수를 생성)
- 연관분석이란
- 연관분석의 문제점 (아이템이 증가할 수록 규칙의 수가 기하급수적으로 증가)
- Apriori
- 연관분석의 아이템 증가 폭을 줄이기 위한 방법
- "빈번한 아이템의 하위 아이템은 또한 빈번할 것이다." 가 기본 전제
- "빈번하지 않은 아이템의 하위 아이템은 또한 빈번하지 않을 것이다." 를 사용
- 지지도가 낮은(최소값) 아이템 규칙을 삭제한다.
- FP-Growth 알고리즘
- Apriori의 속도적인 측면의 단점을 개선한 알고리즘
- Apriori와 비슷한 성능을 보이지만 FP Tree라는 구조를 사용하여 더 빠른 속도를 낼 수 있음
- 아이템간의 연관성을 찾는 것은 어려움
- 컨텐츠 기반 모델
- 사용자가 이전에 구매한 상품 중에서 좋아하는 상품들과 유사한 상품들을 추천하는 방법
- 보통 아이템을 벡터(True, False의 모양) 형태로 표현
- 벡터들간의 유사도를 계산하여 추천하게 되는 알고리즘
- 유사도 함수
- 유클리디안 유사도
- 문서간의 유사도를 계산 (p라는 벡터와 q라는 벡터의 거리를 계산)
- 장점 = 계산이 쉬움
- 단점 = p와 q의 분포가 다르거나 범위가 다른 경우에는 상관성을 놓침
- 두 문서를 비교할 때, 벡터의 차이정도를 비교
- 코사인 유사도
- 문서간의 유사도를 계산
- 장점 = 벡터의 크기가 중요하지 않은 경우에 거리를 측정하기 위한 메트릭 사용 (문서 내에서 단어의 빈도수를 사용하여 확인)
- 단점 = 벡터의 크기가 중요한 경우에는 잘 작동하지 않음
- 피어슨 유사도
- 문서간의 유사도를 계산
- 상관관계를 분석할 때 많이 사용
- 분산과 편차를 사용하여 유사도 측정
- 자카드 유사도
- 문서간의 유사도를 계산
- 집합에서 얼마만큼 겹쳤는지에 대한 유사도 측정
- 유클리디안 유사도
- 컨텐츠의 성질에 따라 유사도 측정을 다르게 사용하여야 함
- TF-IDF
- TF(특정 문서 내에 특정 단어가 얼마나 자주 등장하는지를 의미하는 단어 빈도수)
- IDF(전체 문서에서 특정 단어가 얼마나 자주 등장하는지를 의미하는 역문서 빈도)
- TF와 IDF를 사용하여 문서 내 단어의 가중치를 계산하는 방법
- 핵심어 추출, 문서들 사이 유사도 계산, 검색 결과의 중요도를 정하는 작업 등에 활용 가능
- 관사나 조사와 같은 큰 의미가 없는 단어들을 패널티를 주어서 적절하게 중요한 단어만 잡아내는 기법
- 장점 = 직관적인 해석이 가능
- 단점 = 대규모 말뭉치를 다룰 때 메모리상의 문제가 발생
- 높은 차원을 가짐
- 매우 sparse한 형태의 데이터 (드문드문한 벡터의 데이터 형태)
- Word2Vec
- 통계기반의 방법에서의 단점을 해결한 방법
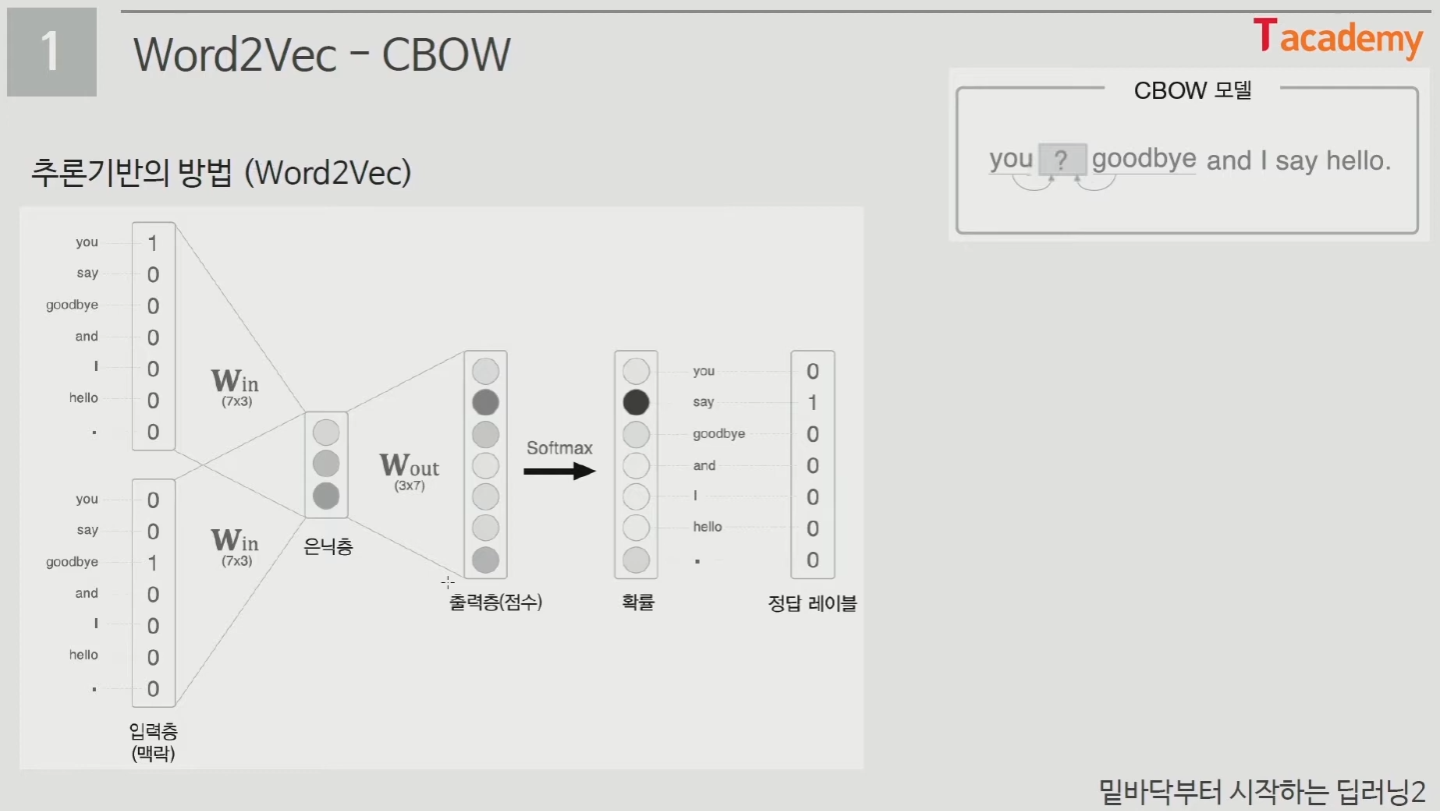
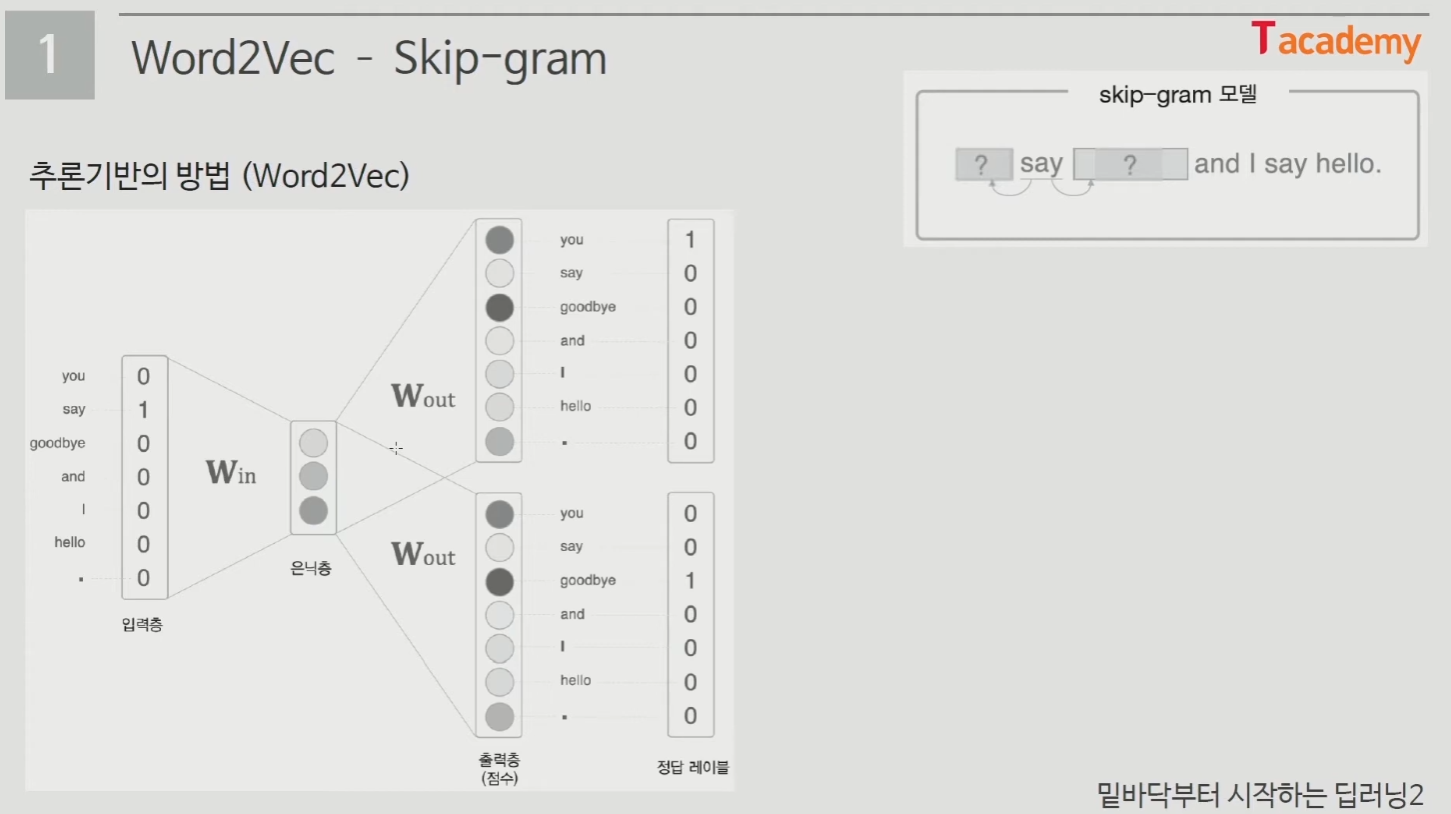
- 추론기반의 방법
- 주변 단어(맥락)가 주어졌을 때, 어떤 단어(중심 단어)가 들어가는지 추측하는 작업
- 단어간 유사도를 반영하여 단어를 벡터화 시키는 임베딩(embedding) 방법론
- "비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다."
- 두 가지의 알고리즘 존재 = CBOW, Skip-Gram
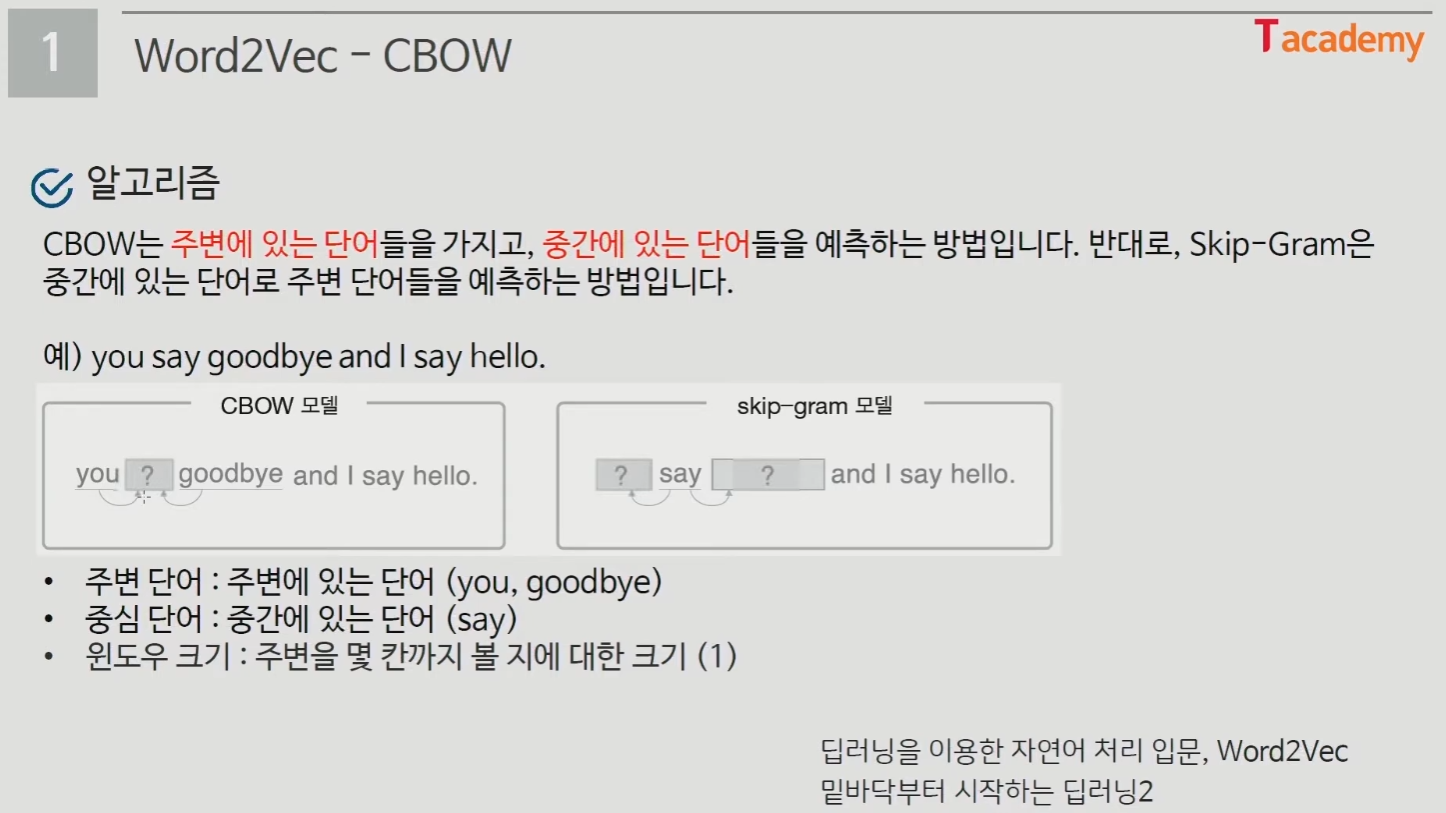
- CBOW
- 주변에 있는 단어들을 가지고 중간의 단어를 예측
- Skip-Gram
- 중간의 단어로 주변 단어를 예측
- 보통 Skip-Gram을 많이 사용 (성능이 우수, 좀 더 어려운 Task를 수행하기 때문)
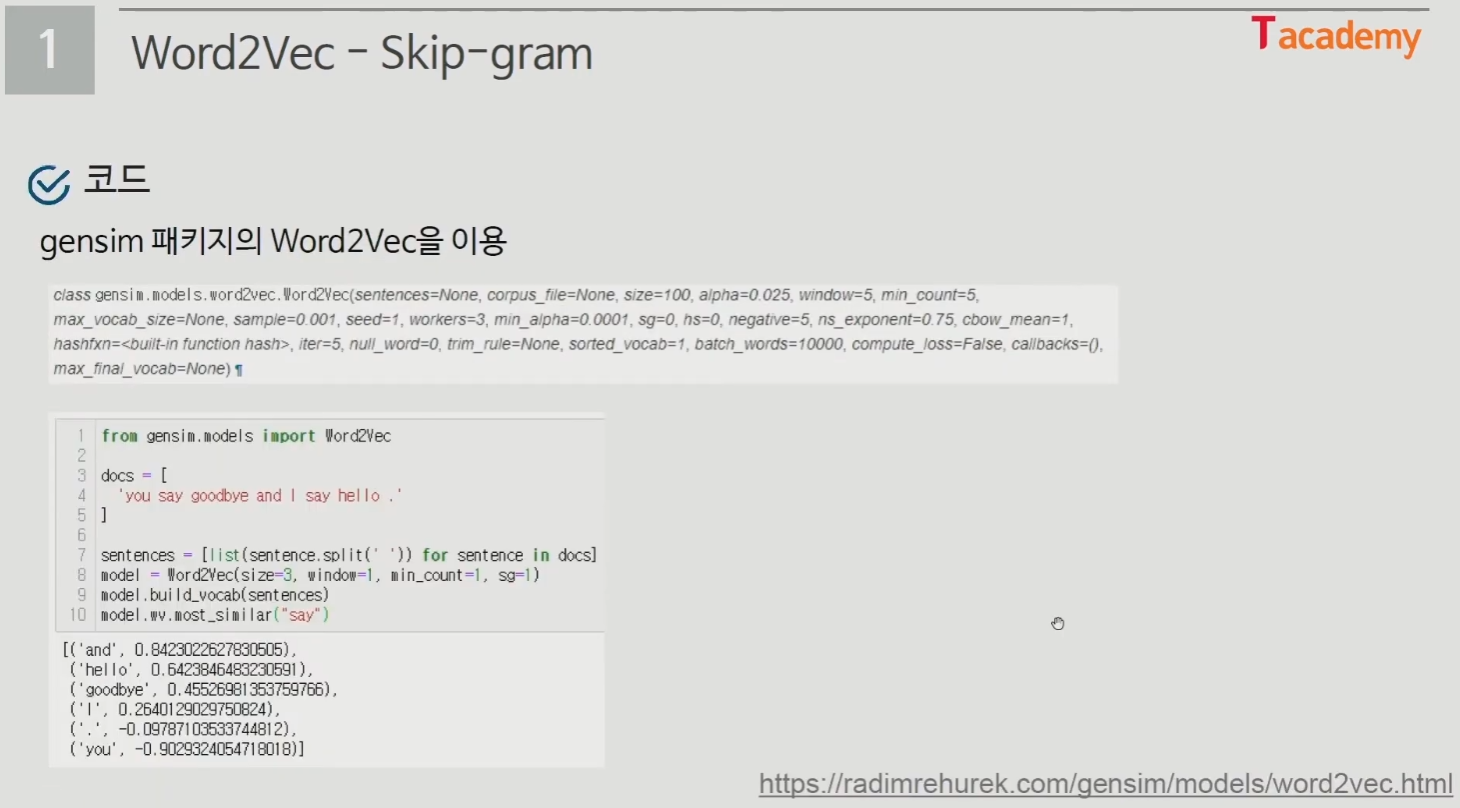
- gensim 패키지의 Word2Vec을 이용

- 컨텐츠 기반 모델 하나만으로는 높은 정확도를 구축하기 힘들기 때문에 협업 필터링 모델도 적절하게 함께 사용
- 협업 필터링 모델
- 사용자의 구매 패턴이나 평점을 가지고 다른 사람들의 구매 패턴, 평점을 통해 추천을 하는 방법
- 추가적인 사용자의 개인정보나 아이템의 정보가 없이도 추천할 수 있음
- 종류는 최근접 이웃기반과 잠재 요인 기반으로 나뉨
- Neighborhood based method
- 메모리 기반 알고리즘
- 협업 필터링을 위해 개발된 초기 알고리즘
- User-based collaborative filtering (사용자의 구매 패턴 혹은 평점과 유사한 사용자를 추천)
- Item-based collaborative filtering (특정 사용자가 준 점수간의 유사한 상품 추천)
- KNN (K Nearest Neighbors)
- 가장 근접한 K명의 Neighbors를 통해 예측하는 방법
- Explicit Feedback = 유저가 자신의 선호도를 직접 표현한 데이터

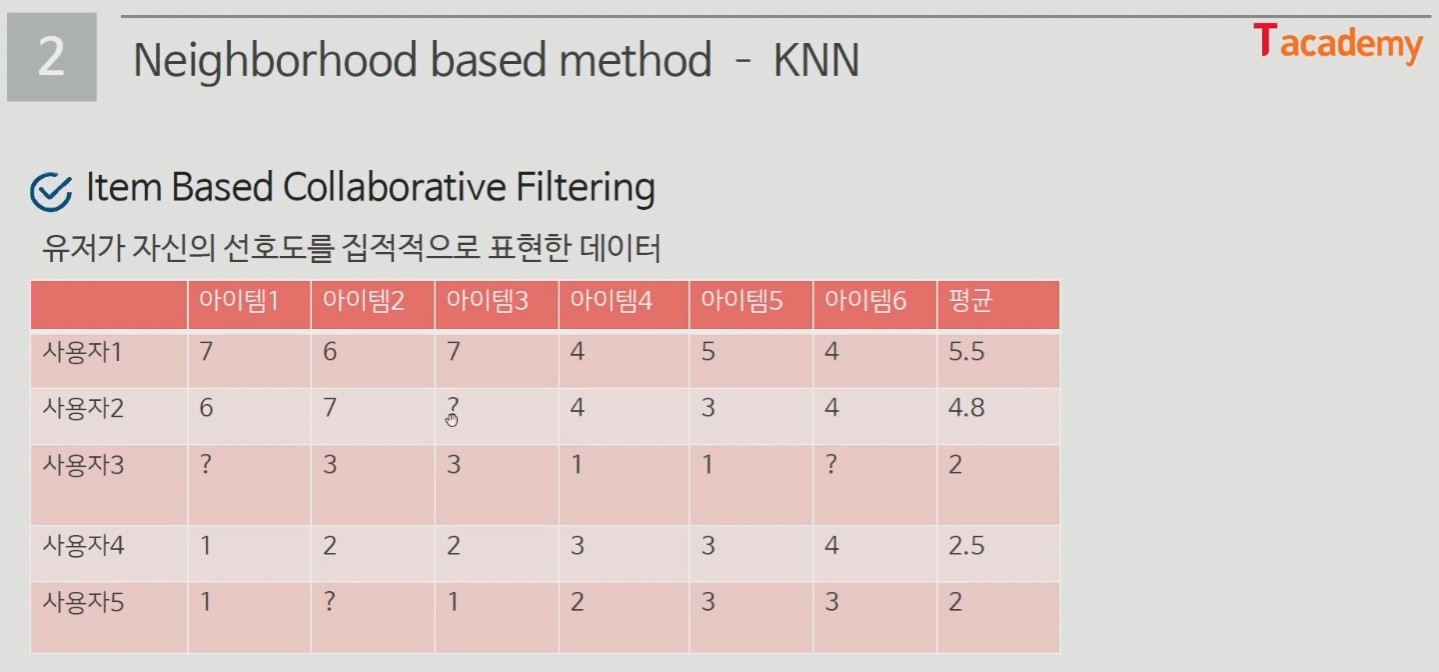

- 잠재 요인 협업 필터링 (Latent Factor Collaborative Filtering)
- Rating Matrix에서 빈 공간을 채우기 위해 사용자와 상품을 잘 표현하는 차원(Latent Factor)을 찾는 방법
- 사용자와 아이템 상호작용 행렬을 곱으로 분해하여 작동
- 원리로는 SGD와 ALS
- SGD
- 고유값 분해(eigen value Decomposition)와 같은 행렬을 대각화 하는 방법
- User Latent와 Item Latent의 곱으로 결과 도출
- 각 평점마다 Gradient Descent 진행 (epoch, 즉 횟수도 여러 번 진행)
- 이로 인한 결과를 도출 (높게 나오면 추천, 낮거나 음수면 비추천)
- 장점 = 매우 유연한 모델로 다른 Loss function을 사용 가능, parallelized(병렬화) 가능
- 단점 = 수렴까지 속도가 매우 느림 (하지만 좋은 성능의 DL 선택시 단점 보완 가능)
- ALS
- SGD는 두 행렬을 동시에 최적화한다면, ALS는 두 행렬 중 하나를 고정시키고 다른 하나의 행렬을 순차적으로 반복하며 최적화 하는 방법
- 기존의 최적화 문제가 convex(볼록한 함수의 형태) 형태로 바뀌어 수렴된 행렬을 찾을 수 있음
- 알고리즘
- 1. 초기 아이템, 사용자 행렬 초기화
- 2. 아이템 행렬 고정 => 사용자 행렬 최적화
- 3. 사용자 행렬 고정 => 아이템 행렬 최적화
- 4. 2번과 3번의 과정 반복
- implicit 패키지의 ALS 사용 가능
- 장점 = 도메인 지식이 필요없음, 사용자의 새로운 흥미 발견에 좋음, 시작단계의 모델로 선택하기 좋음
- 단점 = 새로운 아이템에 대해 다루기 힘듬, side features(고객의 개인 정보, 아이템의 추가 정보 등)를 포함시키기 어려움
- 평가함수
- 추천시스템의 모델을 생성하고 해당 모델이 얼마나 잘 추천하고 있는지에 대해서 평가를 도와주는 함수
- 도메인이나 목적에 따라서 다른 평가함수를 도입해야 한다.
- Accuracy (정확도)
- 사용자가 추천해준 아이템을 선택했는가?
- MAP
- 추천의 순서에 값을 매겨, 먼저 추천해주는 것이 더 큰 의미를 갖다는 상황에서 평가
- NDCG (Normalized Discounted Cumulative Gain)
- Ranking Quality measure
- 검색 알고리즘에서 성과를 측정하는 평가 메트릭
- 사용자마다 추천해 줄 수 있는 아이템 개수가 다를 수 있는데 그 부분을 정규화를 이용해 정렬함
- CG = 추천했을 때의 반영을 어떻게 해줬는지의 값
- DCG = CG에 순서의 중요도를 매겨준 값
- NDCG = DCG에 정규화를 적용한 값
- 실습은 유튜브 영상을 참고하며 진행
출처 : 추천시스템 분석 입문하기 (T아카데미) 정리, https://www.youtube.com/playlist?list=PL9mhQYIlKEhdkOVTZWJJIy8rv6rQaZNNc
토크ON 82차. 추천시스템 분석 입문하기 | T아카데미
T아카데미 온라인 강의- [토크ON세미나] 추천시스템 분석 입문하기 (총6강) ▶ https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=194 [과정 소개] 이번 과정에서는 추천시스템의 전반적인 내용
www.youtube.com
728x90
반응형
'개발 > (3) 머신러닝(ML), 딥러닝(DL)' 카테고리의 다른 글
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 2 (0) | 2023.03.27 |
|---|---|
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 1 (0) | 2023.03.27 |
| YOLO 공식문서 번역 및 학습 (0) | 2022.12.25 |
| K-MOOC 파이썬 머신러닝 공부 2일차 오전 (0) | 2022.11.22 |
| K-MOOC 파이썬 머신러닝 공부 1일차 (0) | 2022.11.21 |