머신러닝의 기초와 용어
1. 머신러닝이란(개념)
- 데이터를 컴퓨터를 통해 함수를 사용해서 스스로 학습시키고 예측을 하는 것을 의미
- 딥러닝도 머신러닝의 일종
- CPU와 GPU(그래픽카드, 병렬 계산) computing
- Learning system의 구성 요소
==> 환경(E, Enviroment), 데이터(D, data), 함수(M, model), 평가(P, Performance)
- 평가 기준 : MSE(제곱 편차 평균)

2. 머신러닝 학습 개념
- Linear Regression : 선형 분석 (input과 out이 관계가 있다.) - MSE
==> 선형적인 관계이므로 ax = y 의 모양으로 발생
==> 완벽히 그리는 것은 불가능에 가깝고, 오차가 적도록 만드는 것이 목표
==> Learning 이란 최적화와 가장 개념이 비슷함
==> 우리가 할 수 있는건, 데이터를 추출하는 것
3. 머신러닝 프로세스 및 활용
- Supervised Learning(지도 학습) : 범주형(강아지, 고양이, 자동차, 비행기, Classification), 연속형(연속적인, Regression)
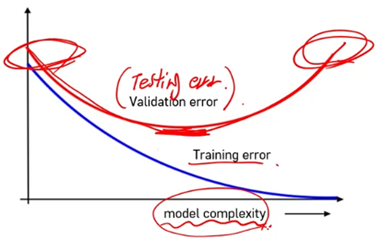
- Generalizaion Error and Hyperparameter
1) Training error : 학습시킨 것에서 발생하는 오류
2) Validation error : 일반적인 오차, 예측 오차
complexity : 복잡성
Hyperparameter : 모형을 구축하고 특성을 규정하는 외적인 요소
4. 머신러닝 프로세스 개요
1) 비즈니스와 데이터에 대한 이해
2) 데이터 전처리
3) Training 과 Test 데이터 나누기
4) 알고리즘을 사용하여 모델(함수) 만들기
5) 모델 적용하고 평가하기
6) 현실에 적용하기(배포)
7) 지식 습득 및 수정
Data 관련 용어
- Dataset : 정의된 구조로 모아져 있는 데이터 집합
- Data Point(Observation) : 데이터 세트에 속해 있는 하나의 관측치
- Feature(Variable, Attribute) : 데이터를 구성하는 하나의 특성(숫자형, 범주형, 시간, 텍스트, 이진형)
- Label(Target, Response) : 입력 변수들에 의해 예측, 분류되는 출력 변수
분류와 회귀
- 분류(Classification) : 종속변수(y)가 범주형일 때 사용하는 모델(입력된 보험 청구권에 대해서 자동심사와 인심사분류)
- 회귀(Regression) : 종속변수(y)가 연속형일 때 사용하는 모델(날씨, 유가, 경제 지표 등을 이용한 주가 예측)
Data 준비 과정
- Dataset Exploration(EDA, Exploratory Data Analysis) : 데이터 모델링을 하기 전에 데이터 변수 별 기본적인 특성 파악
- Missing Value : 일부 데이터가 수집되지 않고 결측치로 남아있는 부분(처리 필요)
- Data types and Conversion : 데이터 형식을 계산할 수 있는 형태로 변환 필요
- Normalization(정규화, Scailing 한다고 표현) : 데이터 변수들의 단위가 크게 다른 경우들은 정규화가 필요
- Outliers : 관측치 중에서 다른 관측치와 크게 차이나는 관측치 처리
- Feature Selection : 많은 변수 중에서 중요한 변수만 선택하기
- Data Sampling : 모델을 검증하거나 이상 관측치를 찾는 모델링을 할 때, 앙상블 모델링을 할 때 가지고 있는 데이터를 일부 추출하는 과정을 거치기도 함
5. Modeling
- Model : 모델은 입력 변수와 출력 변수 간의 관계를 정의해 줄 수 있는 추상적인 함수 구조
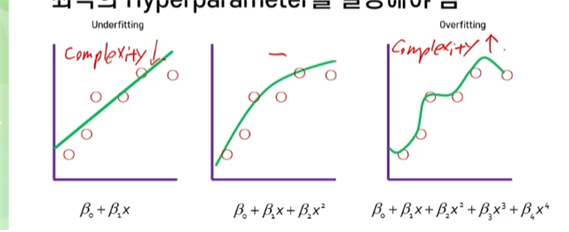
- Underfit : 너무 간단하게 학습한 경우
- Overfit : 너무 깊게 학습한 경우
- Optimal : 적절하게 학습된 경우
6. Modeling 검증
- Training error : training data 의 오차
- Validation error : test data 의 오차
7. 머신러닝 분류 모델링
classification과 regression을 분류하는 기준
출력변수(y)가 연속형이면 Regression, 범주형이면 Classification
Bias-Variance Tradeoff
- 모든 모델은 복잡도를 통제할 수 있는 Hyperparameter를 갖고 있음
- 가장 좋은 성능을 내기 위해 최적의 Hyperparameter를 찾아야 함
- Bias : 치우쳐져 있음, 오차값이 얼마나 떨어져 있는가
- Variance : 모형들이 다양하게 출력하는 변동성
Classification의 예시
범주형(categorical) 종속변수 : Class, Label
제품이 불량인지 양품인지 분류
고객이 이탈고객인지 잔류고객인지 분류
카드 거래가 정상적인지 아닌지
Classification model은 문제 상황에 따라 적합한 모델을 선택해야 함
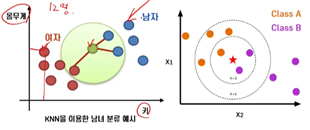
8. K-Nearest Neighbors
K는 임의의 숫자를 의미(Hyperparameter)
두 관측치의 거리가 가까우면 Y도 비슷함
K 개의 주변 관측치의 Class에 대한 majority voting(다수결)
Distance-based model, instance-based learning
출처 : http://www.kmooc.kr/courses/course-v1:SSUk+SSMOOC20K+2022_T1/about / 수업 내용을 듣고 정리함
실습으로 배우는 머신러닝
www.kmooc.kr
'개발 > (3) 머신러닝(ML), 딥러닝(DL)' 카테고리의 다른 글
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 2 (0) | 2023.03.27 |
|---|---|
| 부스트코스 재활용 쓰레기를 활용한 딥러닝 강의 정리 1 (0) | 2023.03.27 |
| 추천시스템 분석 입문하기 (T아카데미) 정리 (0) | 2023.02.15 |
| YOLO 공식문서 번역 및 학습 (0) | 2022.12.25 |
| K-MOOC 파이썬 머신러닝 공부 2일차 오전 (0) | 2022.11.22 |